Class 3: Clustering Algorithms for Cybersecurity#
Caution
Disclaimer
This is an experimental format. The content of this page was adapted from Professor Roman’s Lecture in Fall 2025. Claude 4.5 was used to clean up the audio transcripts and adapt them for this format. AI may make mistakes. If you into any issues please open an Issue or send an email to the TA Sasank
Learning Objectives#
By the end of this session, you will be able to:
Understand the mathematical foundations of clustering algorithms
Apply K-means, GMM, and DBSCAN to cybersecurity data
Recognize when different clustering approaches fail or succeed
Select appropriate clustering methods based on data characteristics
Implement cluster validation techniques
Overview#
Alright everyone, welcome to Class 3.
Let’s recap what we’ve covered so far. We’ve learned several supervised methods:
K-Nearest Neighbors - Classification via neighborhood consensus. You look at what’s similar and determine the threat category based on known labeled examples.
Support Vector Machines - Finding optimal decision boundaries in high-dimensional feature spaces for malware classification.
Random Forest - Ensemble learning providing robust classification through multiple decision trees.
What’s the common thread tying all of these together?
Hint
The label issue Supervised methods require extensive labeled training data to distinguish benign from malicious activities.
And that’s the big problem.
Labeling, it turns out, is extremely challenging for cybersecurity. I’m using a 2017 dataset for this class - there are newer ones from 2022 and 2023, but many of these are synthetic datasets created in laboratory settings specifically so people can train models on them
The Reality of Real-World Data#
When you get into production environments, getting labeled data is incredibly difficult:
Cyber threats evolve faster than our ability to label them - By the time you’ve identified and labeled a threat, attackers have moved on to new techniques.
Zero-day attacks - These exploit previously unknown vulnerabilities. There are no historical signatures, no labels, nothing to train on.
Class imbalance - Attacks represent rare events in typical network traffic. You might have millions of benign events and only a handful of attacks.
Manual labeling is expensive - It’s time-intensive and requires expert domain knowledge. You need security analysts spending hours examining logs to determine what’s actually malicious.
The “Unknown Unknowns” Framework#
Let me frame this using a concept from intelligence analysis:
Known Knowns - These are documented attack signatures, indicators of compromise (IOCs), and established threat patterns with clear detection rules. Your signature-based systems handle these well.
Known Unknowns - These are suspected attack vectors and emerging threats without specific signatures or clear indicators. You know something might be out there, but you don’t know exactly what it looks like.
Unknown Unknowns - These are completely novel attack methods, threat actors, and exploitation techniques never before observed. This is where traditional security fails completely.
Why Traditional Detection is Failing#
Let me walk you through the cybersecurity imperative here:
Signature-Based Detection is fundamentally reactive. It requires known attack patterns and signatures. It completely fails against novel threats and sophisticated evasion techniques.
Advanced Persistent Threats (APTs) run long-term, stealthy campaigns using legitimate administrative tools and techniques specifically to avoid detection.
“Living off the Land” (LotL) Attacks abuse legitimate system tools - PowerShell, WMI, PsExec - making detection extremely challenging. These tools are supposed to be there, used by administrators every day.
The critical result?
Important
The Limitation of Traditional Systems Traditional antivirus and intrusion detection systems consistently miss sophisticated threats that blend with normal administrative activities.
Real-World Impact#
Let me give you some real examples:
NotPetya (2017)#
Used legitimate PsExec for lateral movement while masquerading as ransomware. It evaded signature-based detection during initial propagation phases because it was using a tool that was supposed to be there.
SolarWinds (2020)#
Supply chain attack that hid malicious code within normal software update processes. It remained undetected for months because it came through legitimate channels. How do you detect a threat when it’s delivered by your trusted update system?
Volt Typhoon (2023)#
This PRC-sponsored group used Living off the Land techniques for over five years, completely bypassing traditional detection systems. Five years! Using legitimate tools the entire time.
The critical pattern across all these attacks is they successfully bypassed signature-based detection by leveraging legitimate tools and processes. This demonstrates the urgent need for behavioral analysis approaches.
We need to stop asking
Is this a known attack?
and start asking
What does normal look like?
Enter Unsupervised Learning#
This is where unsupervised learning comes in. Unsupervised learning is great for:
Pattern Discovery - Algorithms find hidden patterns and structures in data without requiring pre-labeled examples.
Normality Modeling - We shift focus from attack classification to establishing baselines of normal behavior.
Deviation Detection - We identify significant departures from established behavioral baselines.
The key insight: instead of asking “Is this a known attack?”, we ask “Does this behavior deviate significantly from established norms?”
Hint
Ask Different Questions “Does this behavior deviate significantly from established norms?”
Clustering Approach#
The core function of unsupervised learning is to identify “normal” by grouping (or clustering) similar data points, allowing anomalies to stand out.
Think about normal behaviors in your network:
Consistent web browsing patterns
Regular email communication flows
Standard file transfer behaviors
Routine system administration tasks
When you establish these patterns, attacks stand out. Abnormal behavior is not in the same cluster in your parameter space as your normal behavior. Examples include:
Unusual communication patterns, like connections to command and control servers
Abnormal resource usage, like unexpected crypto-mining activity
Strange temporal patterns, like logins at odd hours when users are typically offline
Outlier behaviors that don’t align with any established norms
These abnormal behaviors may even be context dependent. Normal for someone in finance but not sompeone in operations.
Clustering Philosophies#
Today we’re going to cover three fundamentally different approaches to clustering:
Centroid-Based: K-means#
Philosophy: Groups form around central points.
Assumption: Clusters are spherical and similarly sized.
Best for: Discovering well-separated, distinct attack types or user behavior profiles.
Think of it like this: K-means says “every cluster has a center, and things near that center belong together.” It’s fast, it’s simple, it’s intuitive.
Distribution-Based: Gaussian Mixture Models (GMM)#
Philosophy: Data originates from a mixture of probability distributions.
Assumption: Clusters can be elliptical and probabilistic, allowing for overlap.
Best for: Modeling uncertain classifications or overlapping behavioral patterns.
The key difference is that GMM doesn’t just say “you’re in cluster A or cluster B” - it says “you’re 70% likely to be in cluster A and 30% likely to be in cluster B.” It gives you probability, uncertainty quantification.
Density-Based: DBSCAN#
Philosophy: Groups are defined by regions of high data point density.
Assumption: Clusters can be arbitrary shapes, with automatic noise detection.
Best for: Identifying irregular attack patterns and automatically discerning anomalies from noise without knowing the number of clusters ahead of time.
Why this matters: DBSCAN doesn’t care about cluster shape. It finds dense regions and says “that’s a cluster.” Everything else is just Noise. Potential anomalies.
Each approach offers unique strengths for modeling normal behavior and detecting anomalies in complex cybersecurity datasets.
When you’re doing clustering for cybersecurity, you’re trying to answer three fundamental questions:
Important
The Three Key Questions
How Many Groups?
What Shape?
Which Don’t Belong?
The frist thing you need to do is determine the optimal number of natural behavioral clusters inherent in your network or system data.
Once you do that, the next step is to understand the geometric structure and distribution of these behavioral patterns to accurately model normal activity.
After you have modeled normal activity you need a way to identify data points that do not fit into any established behavioral group, indicating potential anomalies or threats.
Different clustering algorithms answer these questions differently, and that’s what we’re going to explore in the notebook.
Setup and Imports#
Alright, let’s get into the technical details. Now would be a good time to open the notebook (or the lab assignment) and follow along. The below cell involves all of the standard notebook setup that you will need to run this on your own. It is hidden to minimize impact to flow. All code cells can be inspected by clicking on the drop down on the right
Visualizing the Problem#
In the notebook, we’re going to start with synthetic data that represents cybersecurity scenarios. This lets us understand the algorithms before applying them to real-world data.
Here’s the challenge we’re facing: most cybersecurity data is unlabeled.
Network traffic logs - You’ve got millions of flows. Which ones are attacks?
User behavior - What constitutes “normal” versus “suspicious”?
System events - Which patterns actually indicate a compromise?
The solution is unsupervised learning to find natural groupings and outliers.
Understanding the Synthetic Data
In the first code cell, we’re creating synthetic cybersecurity-like data to demonstrate the problem:
Normal web traffic - Consistent patterns centered around certain values
Normal email traffic - Different patterns from web traffic
Normal file transfers - Yet another distinct behavioral pattern
DDoS attack - An attack pattern we don’t initially know about
Data exfiltration - Another hidden attack pattern
When we plot this data, you’ll see just gray points. No labels. No indication of what’s what. This is what you’d face in the real world - just data, and you need to figure out what’s normal and what’s not.
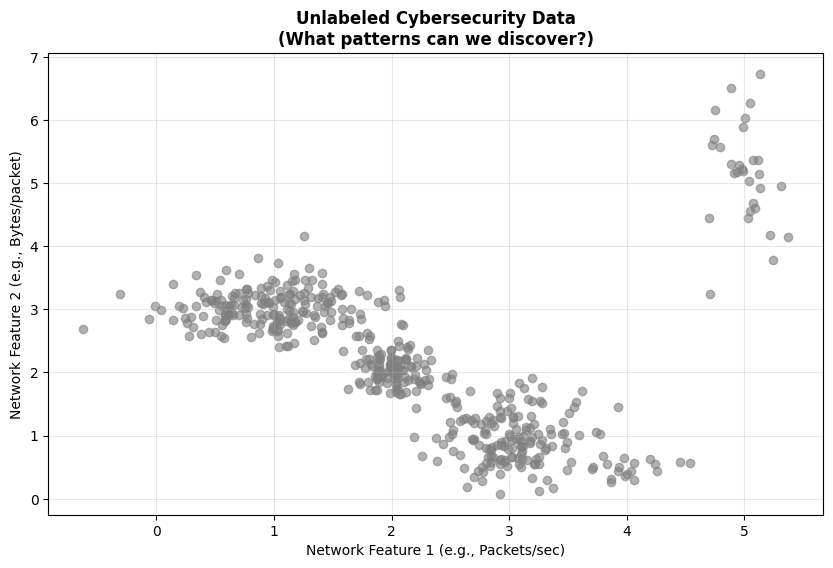
K-means Clustering#
The Mathematical Foundation#
Now let’s talk about K-means. The mathematical objective is to minimize the within-cluster sum of squares (WCSS). This is given by the formula:
Where:
\(k\) = number of clusters
\(C_i\) = cluster \(i\)
\(\mu_i\) = centroid of cluster \(i\)
\(||x - \mu_i||^2\) = squared Euclidean distance
The formula might look intimidating, but the concept is simple: for each cluster, you’re summing up the squared distance from every point to that cluster’s center. You want to minimize that total across all clusters.
The algorithm is beautifully simple:
Algorithm Steps:
Initialize: Randomly pick \(k\) points as your initial centroids
Asign: Assign each point to nearest centroid
Update: Update centroids to cluster means: \(\mu_i = \frac{1}{|C_i|} \sum_{x \in C_i} x\)
Repeat: Repeat steps 2-3 until he centroids stop moving, (i.e. convergence)

Watch what happens iteration by iteration. You’ll see the centroids (marked with X’s) start at random positions, then gradually move toward the center of their clusters. The cluster assignments change as the centroids move. Usually, you’ll converge in just a few iterations.
This is the power of K-means - it’s fast and intuitive. You can literally watch it find patterns.
**K-means Algorithm Visualization**
Watch how centroids move and clusters form...
Converged after 6 iterations
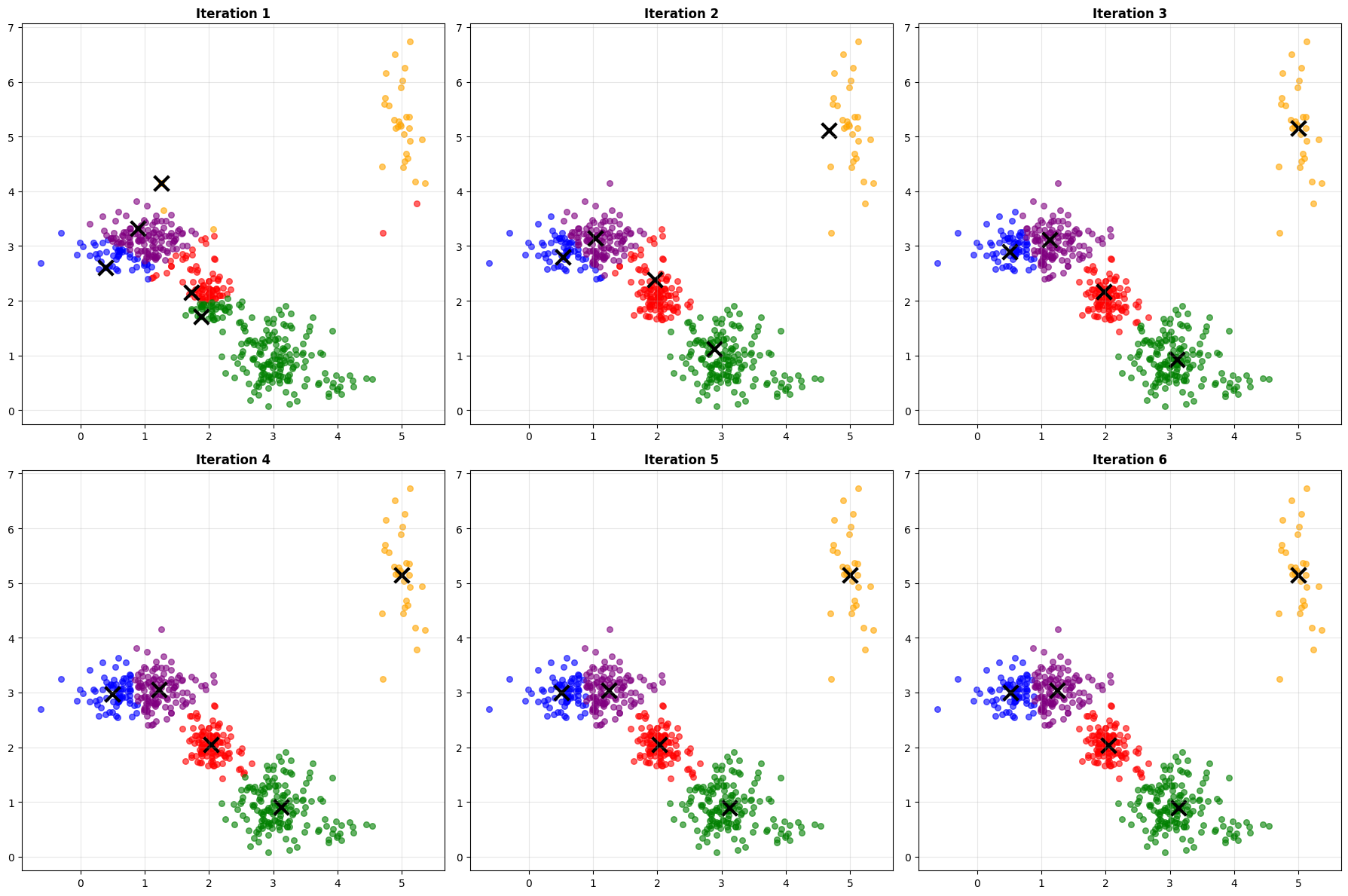
Final WCSS: 117.54
Key K-Means Hyperparameters#
Like other models, hyperparameter selection influences performance. Below are some of the key hyperparameters involved in K-means.
Parameter |
Description |
Default |
Impact |
|---|---|---|---|
|
Number of clusters (k) |
Must specify |
Critical: Determines cluster count |
|
Centroid initialization |
|
Affects convergence speed/quality |
|
Number of random initializations |
|
Helps avoid local minima |
|
Maximum iterations |
|
Controls convergence |
|
Convergence tolerance |
|
Stopping criteria precision |
The Parameter Selection Challenge#
But here’s the big question:
How do we choose \(k\) (number of clusters)?
This is one of the fundamental challenges in unsupervised learning. We have two main methods:
Elbow Method#
Plot WCSS versus K
Look for the “elbow” where improvement diminishes
It’s called the elbow method because the curve looks like an arm, and you’re looking for the elbow joint
Silhouette Analysis#
Measures how similar a point is to its own cluster compared to other clusters
Range from -1 to 1, higher is better
Gives you a quality score for each K value
The Silhouette Coefficient is given by the equation
\(s(i) = \frac{b(i) - a(i)}{\max(a(i), b(i))}\)
Where:
\(a(i)\) = average intra-cluster distance for point \(i\)
\(b(i)\) = average distance to nearest cluster for point \(i\)
Range: \([-1, 1]\) (higher is better)
Look at the output from the code below:
**Analyzing optimal number of clusters...**
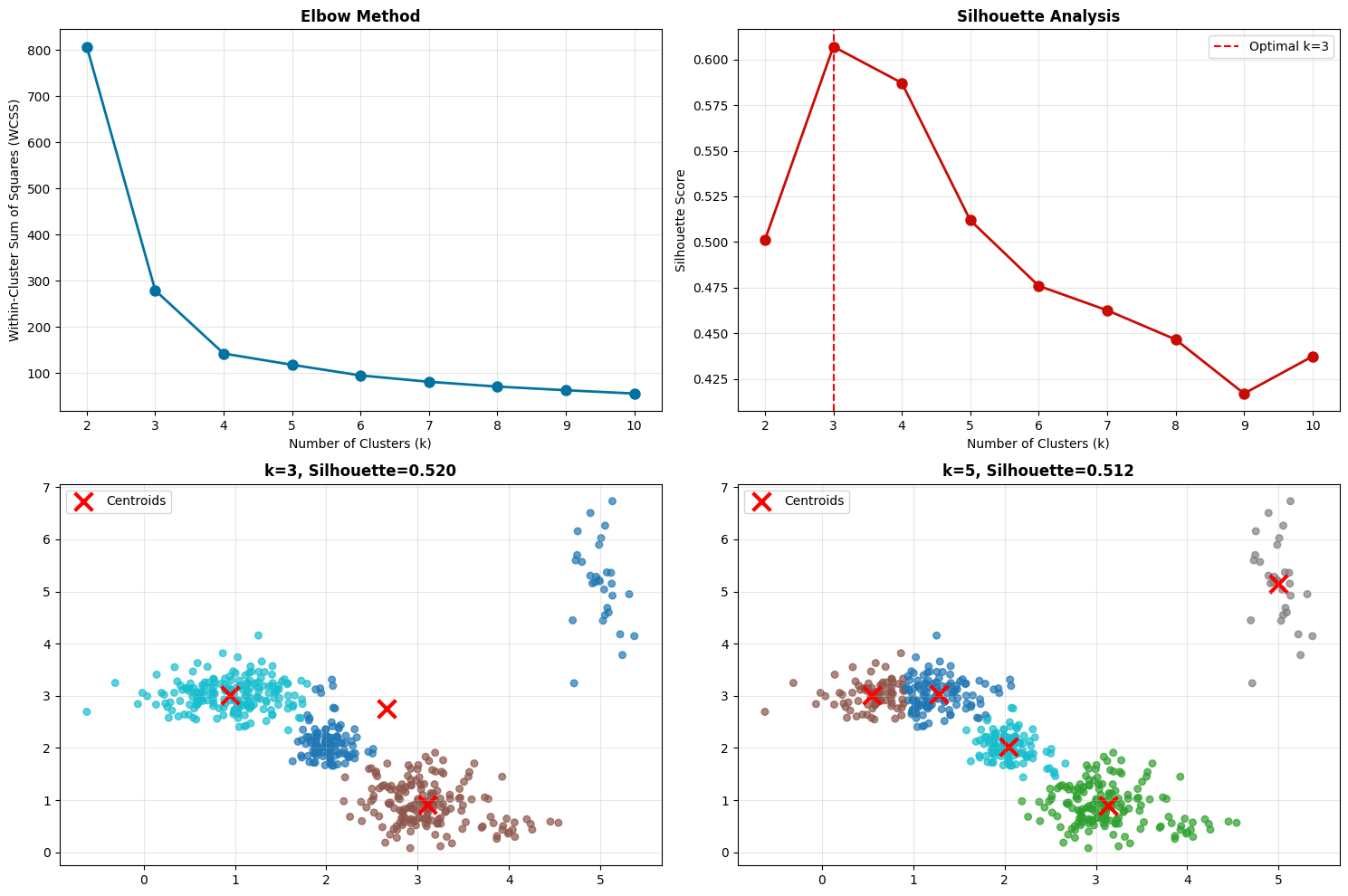
**Analysis Results:**
Optimal k (silhouette): 3
Best silhouette score: 0.607
True number of groups: 5 (3 normal + 2 attacks)
What do you notice? Sometimes the elbow method and silhouette analysis don’t agree! The elbow might suggest K=5, but silhouette peaks at K=3.
This is completely normal and actually an important lesson - clustering is often subjective. There isn’t always a “right” answer. You need to:
Consider your domain knowledge (the cybersecurity context)
Try multiple values and validate results
Use ensemble methods or different algorithms
Accept that there might not be a perfect answer!
When K-means Fails#
K-means makes some strong assumptions:
K-means Assumptions:
Clusters are spherical (circular/elliptical)
Clusters have similar sizes
Clusters have similar densities
All features are equally important
Note
Assumptions Real-world cybersecurity data violates these assumptions all the time!

Look at these three scenarios:#
Non-spherical clusters - Attack campaigns might form crescent or curved patterns. K-means tries to fit spherical clusters and fails.
Different densities - Normal traffic might be very dense (lots of similar flows), while attack traffic is sparse. K-means struggles because it assumes similar densities.
Different sizes - You might have major attack types (many instances) and minor attack types (few instances). K-means tends to split large clusters and merge small ones.
**When K-means Struggles: Cybersecurity Scenarios**
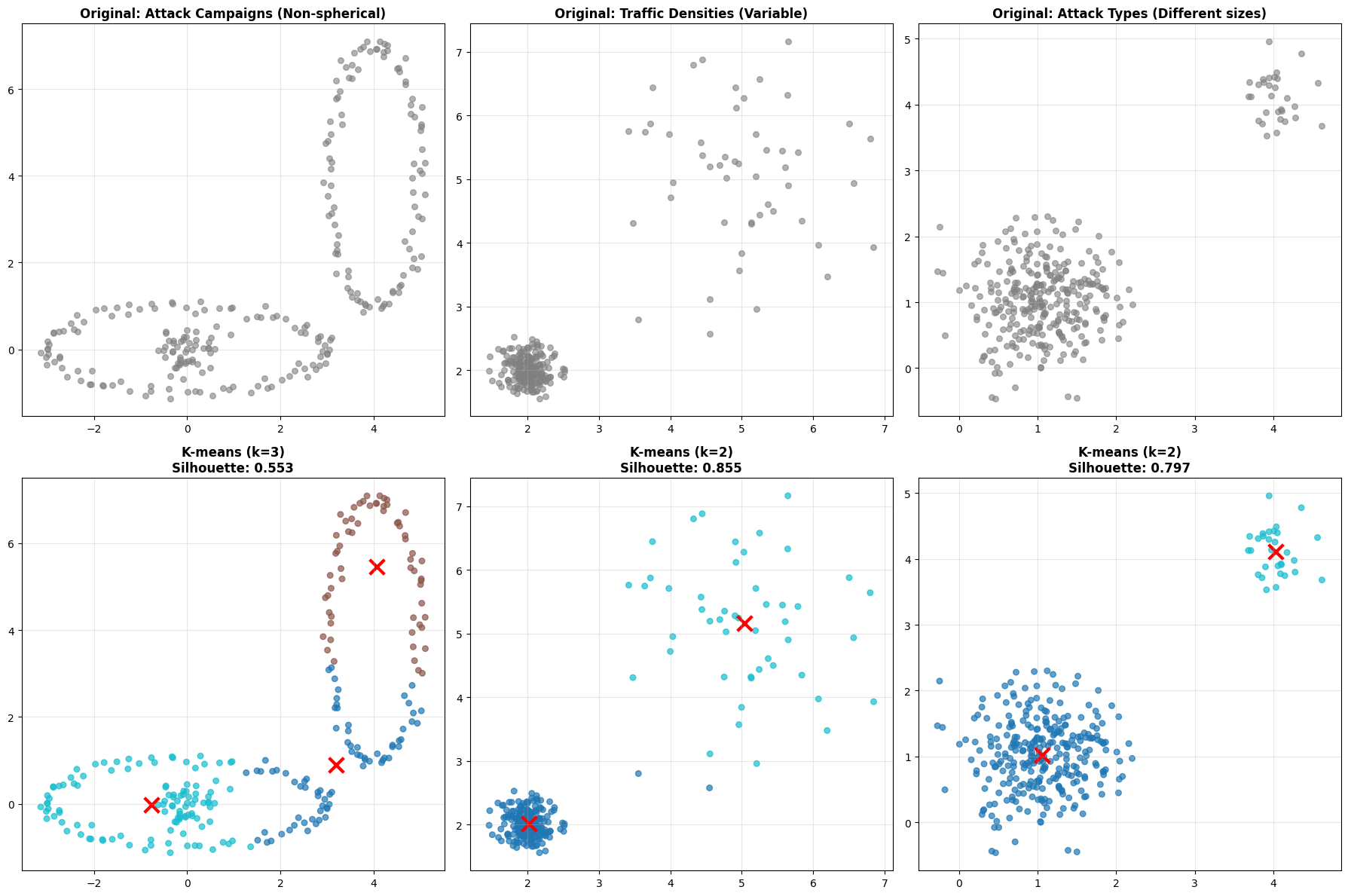
**Key Insight**: K-means assumes spherical, similar-sized clusters
**Cybersecurity Reality**: Attack patterns are often irregular and varied
Note
Key Insight K-means assumes spherical, similar-sized clusters. In reality attack patterns are often irregular and varied.
This is why we need more sophisticated methods.
Gaussian Mixture Models - Adding Flexibility#
GMM takes a probabilistic approach. Instead of saying “this point belongs to cluster A,” it says “this point has a 70% probability of belonging to cluster A and 30% probability of belonging to cluster B.”
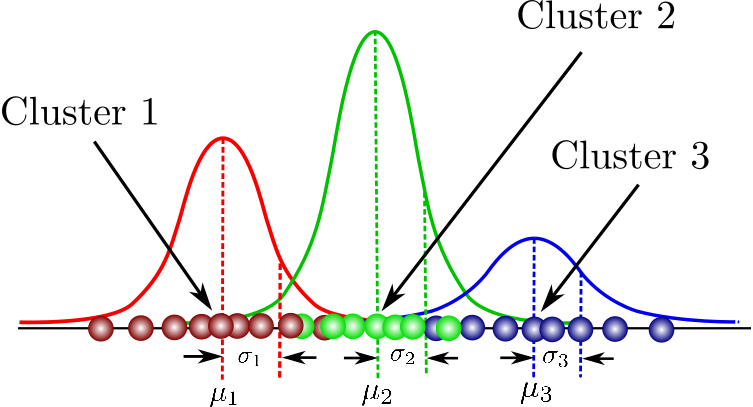
Mathematical Foundation#
Note
The Assumption GMM assumes your data comes from a mixture of Gaussian (normal) distributions.
In a GMM each cluster is defined by:
A mean (\(\mu\)) - the center
A covariance matrix (\(\sigma\)) - the shape and orientation
A mixing coefficient (\(\pi\)) - how prevalent this cluster is
This flexibility allows GMM to model elliptical clusters with different shapes and orientations. One of the key advantages of a GMM is that it defines a probaility density function given by:
Where:
\(\pi_k\) = mixing coefficient (weight) for component \(k\)
\(\mathcal{N}(x | \mu_k, \sigma_k)\) = multivariate Gaussian with mean \(\mu_k\) and covariance \(\sigma_k\)
\(\sum_{k=1}^{K} \pi_k = 1\)
This enables you to set a liklihood threshold instead of a distance threshold when identifying if a certain event should be considered normal or abnormal.
THe Key Advantages over K-means#
Soft clustering: Points can belong to multiple clusters with probabilities
Flexible shapes: Elliptical clusters (not just circular)
Variable sizes: Different cluster covariances mean clusters can be different sizes and shapes. Look back at the previous embeddings of CICIIDS dataset to see that clusters have a high degree of variance
Uncertainty quantification: Probability of cluster membership. This tells you when the model is uncertain, which is valuable information.
GMM vs K-means Comparison#
**GMM vs K-means: Handling Complex Cluster Shapes**
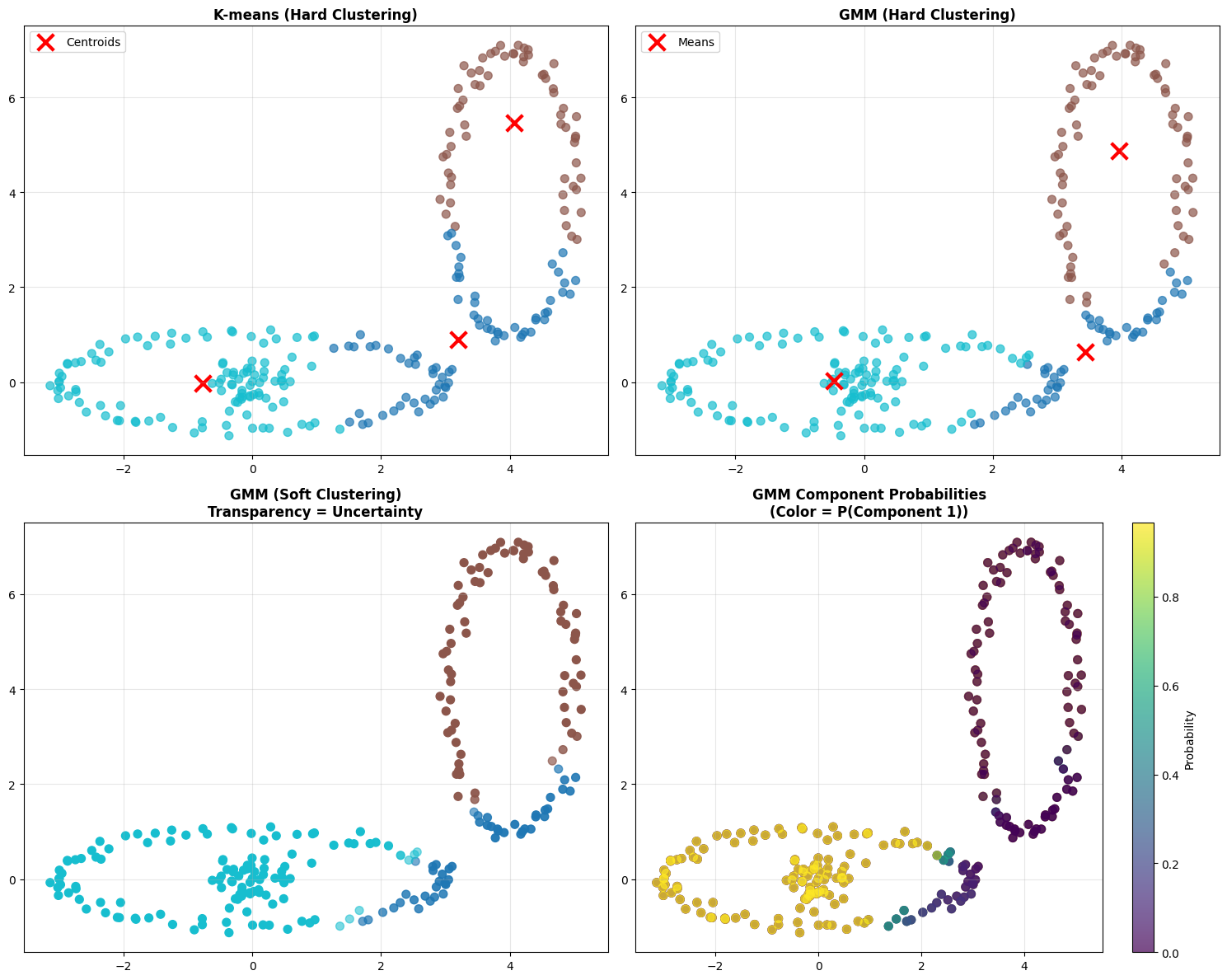
**Performance Comparison:**
K-means Silhouette: 0.553
GMM Silhouette: 0.482
**GMM Advantages:**
- Provides uncertainty measures
- Handles elliptical clusters
- Soft cluster assignments
**Mathematical Insight:**
K-means minimizes: Σ||x - μ||²
GMM maximizes: Σ log[Σπₖ N(x|μₖ,Σₖ)]
Result: GMM can model elliptical clusters with different orientations
Look at the four plots:
Top left - K-means hard clustering. Each point is definitively assigned to one cluster.
Top right - GMM hard clustering. Using the maximum probability, each point gets a single assignment. Might look similar to K-means at first glance.
Bottom left - GMM soft clustering. The transparency shows certainty. Transparent points are uncertain - they could belong to multiple clusters. Opaque points are definitely in their assigned cluster.
Bottom right - GMM component probabilities. This shows the probability surface for one component. You can see how probability gradually decreases as you move away from the cluster center.
Note
The mathematical insight:
K-means minimizes: Σ||x - μ||²
GMM maximizes: Σ log[Σπₖ N(x|μₖ,Σₖ)]
Result: GMM can model elliptical clusters with different orientations.
The Parameter Selection Dilemma - Again#
Sometimes methods disagree even more dramatically with GMM. GMM typically relies on K-means (default) to initialize the centers. There are other options. such as random or k-means++ which balance initialization speed with convergence quality
Parameter |
Default Value |
Description |
|---|---|---|
|
1 |
Most critical parameter - Number of mixture components/clusters |
|
‘full’ |
Type of covariance: ‘full’ (most flexible), ‘tied’, ‘diag’, or ‘spherical’ |
|
100 |
Maximum number of iterations |
|
1 |
Number of initializations to perform (helps avoid local minima) |
The GMM models finds the ideal centers through an initialization phase followed by a Refintement using the Expectation-maximization (EM) algorithm.
THe EM Algorithm is based on Baye’s theorem and goes through an iterative two-step process: *1. E-step (Expectation) where it calculate the probability that each data point belongs to each Gaussian (i.e. cluster assignments) or more often called called the posterior probability. It is essentially using Bayes’ rule to determine how much each component “explains” each data point.
M-step (Maximization) where it updates the parameters (i.e. means (cluster centers), covariances, and mixture weights) to maximize log-likelihood given the posterior probabilities calculated in step 1. i.e. we want the model to provide a higher “confidence” that the point belongs to one of the Gaussian Clusters - and we maximize this across all points.
See also
For a deeper dive
We won’t go in the math here. But for a deeper dive check out the notes from Andrew Ng CS229
What happens when methods disagree?
Sometimes elbow method and silhouette analysis suggest different values of \(k\). This is common in real-world data and represents an important learning moment.
Practical Approach:
Consider domain knowledge - Do you expect 3 or 5 types of behavior in this network? (although this is rarely practical in complex systems, semi-supervised approaches may enable exact cluster definitiions)
Try multiple values and validate - Don’t just pick one and call it done
Use ensemble methods - Sometimes combining multiple values of K works better
Accept uncertainty - There might not be a perfect answer!
**When Methods Disagree: A Real-World Challenge**
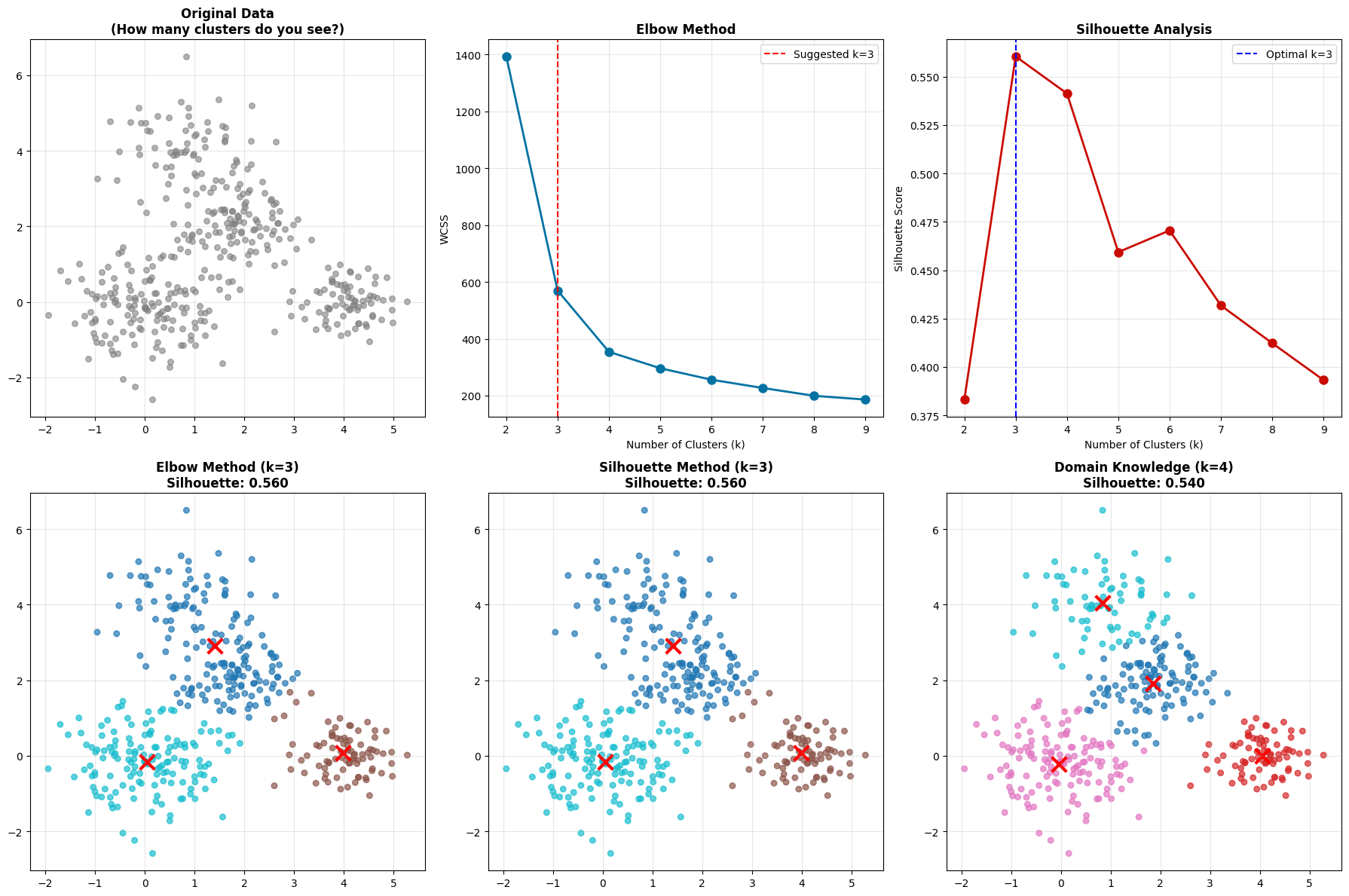
**Method Disagreement Analysis:**
Elbow method suggests: k = 3
Silhouette method suggests: k = 3
**What do we do when methods disagree?**
1. Consider domain knowledge (cybersecurity context)
2. Try multiple values and validate results
3. Use ensemble methods or different algorithms
4. Remember: There might not be a 'perfect' answer!
**Key Learning**: Clustering is often subjective!
**Cybersecurity Insight**: Domain expertise is crucial for validation
Hint
Insight Data Processing is just as important in unsupervised as it is in supervised learning.
Part 4: DBSCAN - A Different Approach#

Density-Based Spatial Clustering of Applications with Noise or more commonly referred to as DBSCAN is fundamentally different from K-means and GMM. Instead of asking “how many clusters?” it asks “where are the dense regions?
Mathematical Foundation#
There are several Key Concepts to keep in mind:
Core Point: A core point is one with at least a
min_samplesneighbors within a distanceeps. These are considered in the “heart” of the cluster.Border Point: A Non-core point within the distance
epsof a core pointNoise Point: Neither core nor border (potential anomalies!)
Intuitively this would be like looking at a groups of people at a tailgate. If they are within 5 feet of 4 friends then they are a core point in the group. If they are only within 5 feet of 1 or 2 friends within that core group, then they are still in the group, but on the edge. If they are outside 5 feet, they aren’t in any group.
Mathematical Definitions:
ε-neighborhood: \(N_{\varepsilon}(p) = \{q \in D | dist(p,q) \leq \varepsilon\}\)
Core point: \(|N_{\varepsilon}(p)| \geq MinPts\)
Directly density-reachable: \(q \in N_{\varepsilon}(p)\) and \(p\) is core
Density-reachable: Chain of directly density-reachable points
The Algorithm
Algorithm:
For each unvisited point \(p\):
Find its \(\varepsilon\)-neighborhood (\(N_{\varepsilon}(p)\)) - all points within distance \(\varepsilon\)
If it has at least
min_samplesneighbors (\(|N_{\varepsilon}(p)| \geq MinPts\)) then start a new clusterAdd all density-reachable points to cluster
Mark isolated points as noise
Key Advantages:
No need to specify number of clusters
Finds arbitrary cluster shapes, Non-spherical, irregular patterns are fine
Automatically identifies outliers/anomalies
Robust to noise as unlike the other methods it doesn’t try to force every point into a cluster
Key DBSCAN Hyperparameters**#
Parameter |
Description |
Default |
Impact |
|---|---|---|---|
|
Maximum distance between points |
Must specify |
Critical: Controls cluster boundaries |
|
Minimum points in neighborhood |
|
Major: Determines core/noise classification |
|
Distance metric |
|
How distances are calculated |
|
Neighbor search method |
|
Performance optimization |
The two critical parameters are:
eps- Maximum distance between points in a cluster. Too small, everything is noise. Too large, everything is one cluster.min_samples- Minimum points to form a dense region. Too small, noise becomes clusters. Too large, real clusters become noise.
Let’s go back to the same dataset we used before and watch what happens when we change eps. With eps=0.3, you might get many small clusters and lots of noise. With eps=1.0, clusters merge together. You’re looking for the sweet spot.
Hint
Hint This is a great place to apply hyperparameter search methods from last class
**DBSCAN: Handling Complex Cluster Shapes**
Perfect for cybersecurity data with irregular attack patterns!
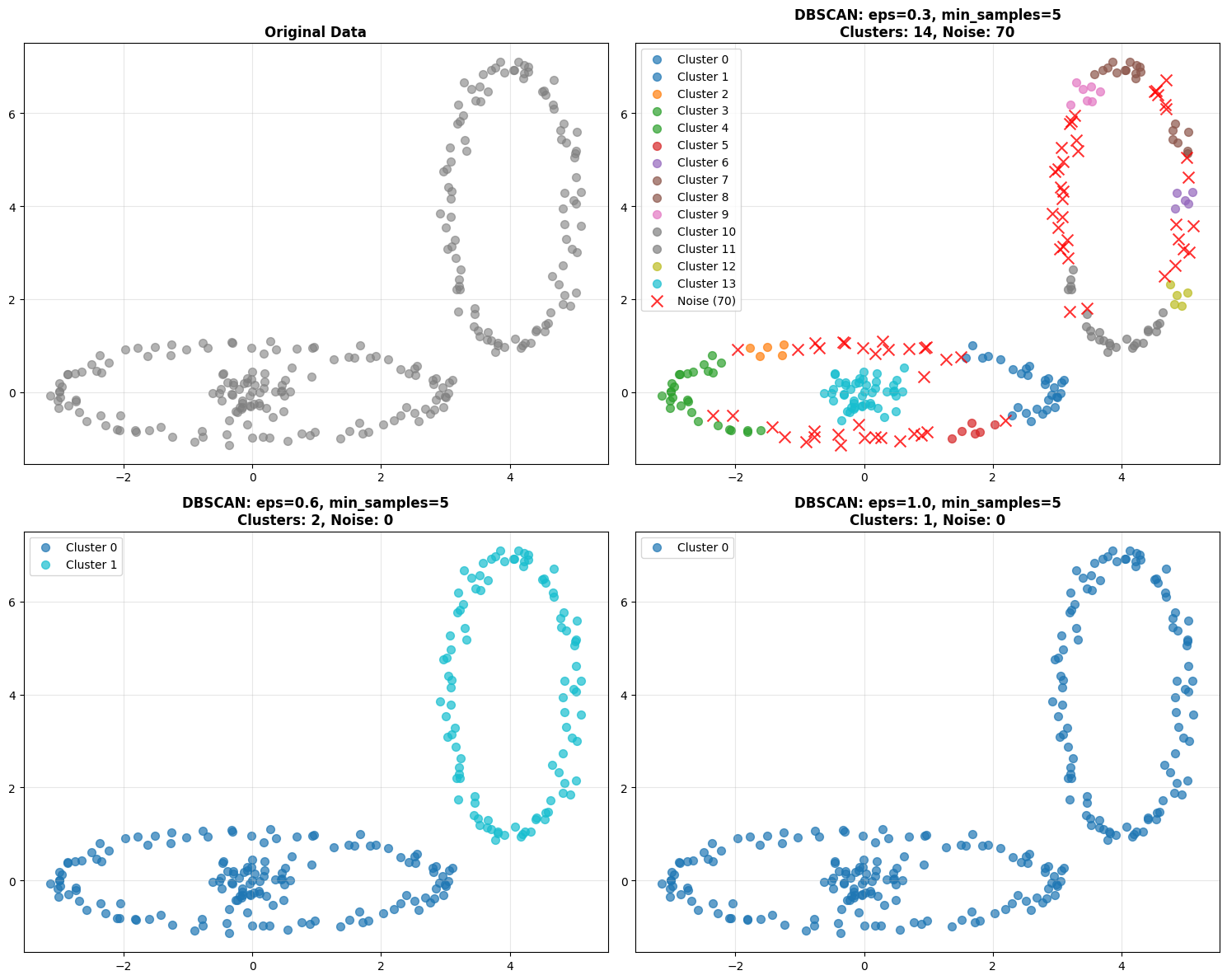
**Finding Optimal eps Parameter**
Method: k-NN distance plot (k = min_samples - 1 = 4)
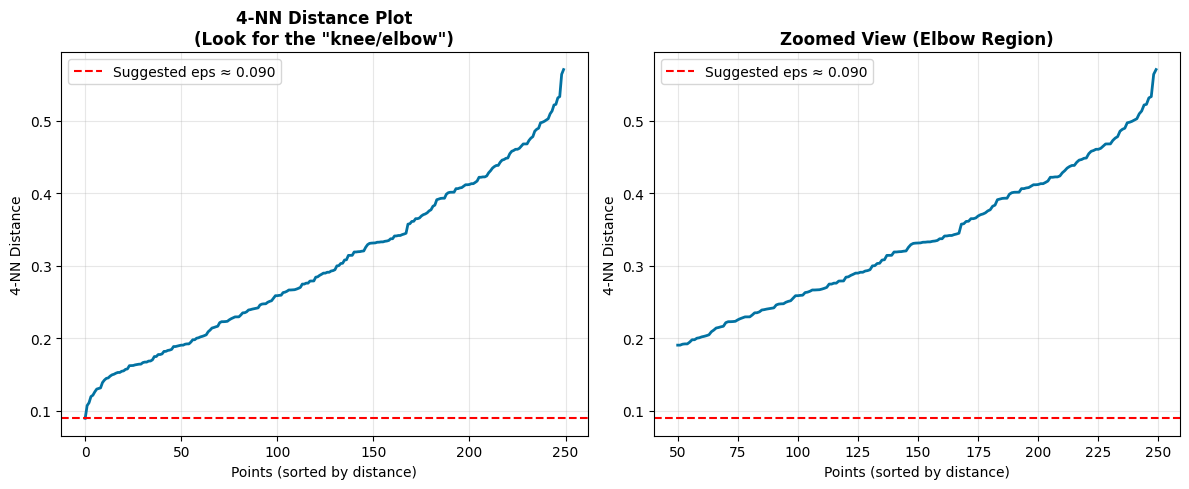
**DBSCAN Key Advantages for Cybersecurity:**
✓ No need to specify number of attack types (clusters)
✓ Finds irregular attack patterns (non-spherical clusters)
✓ Automatically identifies anomalies (noise points)
✓ Robust to outliers in normal traffic
Comprehensive Method Comparison#
Now let’s compare all three methods on the same dataset to understand their strengths and weaknesses.
Hint
Explore how changing the parameters such as k, eps, etc. impacts the output. This dataset is intentionally spherical with some outlier noise.
**Comprehensive Method Comparison**
Testing all three methods on complex cybersecurity-like data...
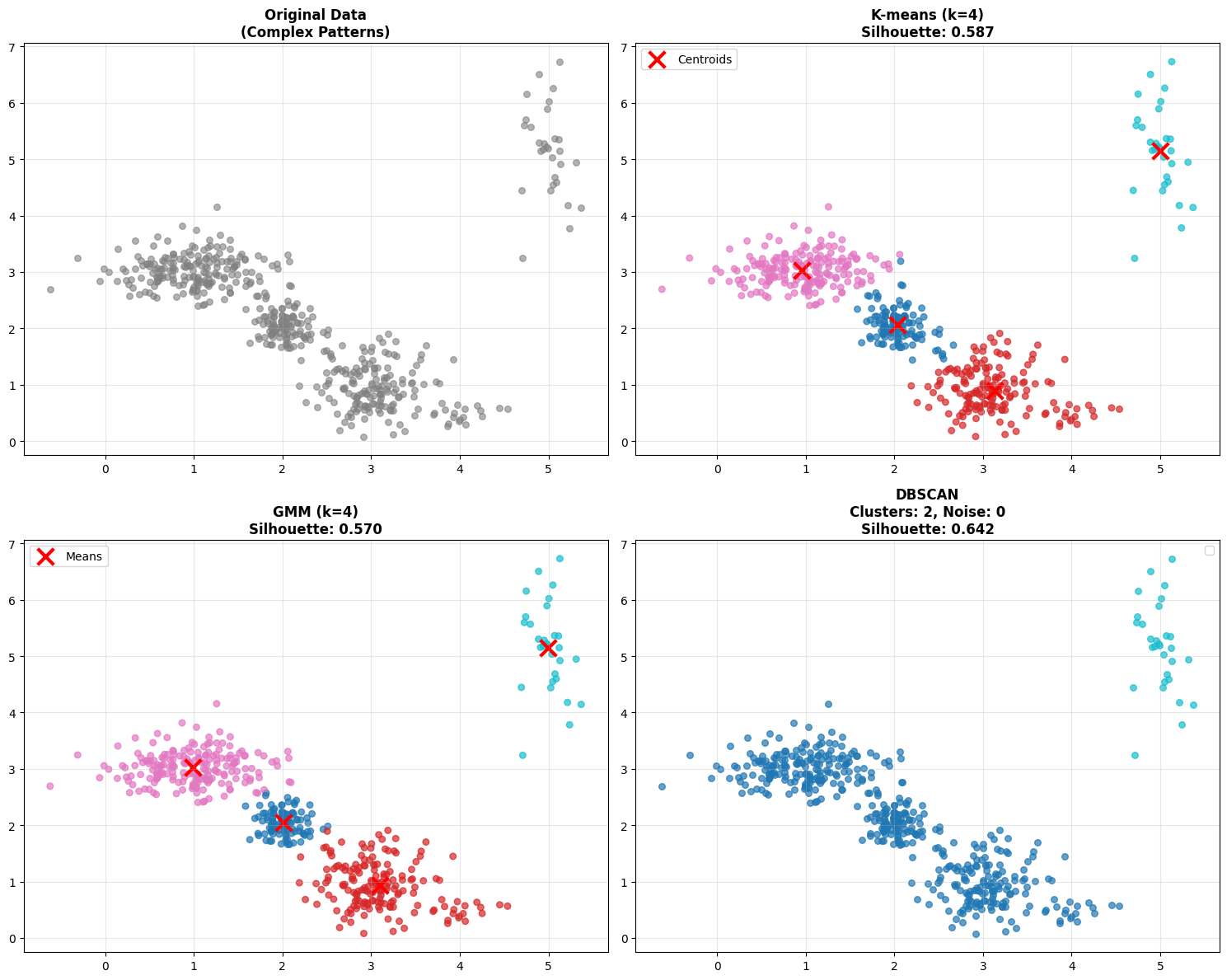
**Method Comparison Summary:**
Method Clusters Noise Silhouette Key Strength
=================================================================
K-means 4 0 0.587 Fast, simple
GMM 4 0 0.570 Probabilistic, flexible shapes
DBSCAN 2 0 0.642 Auto-detects anomalies
**Key Insights for Cybersecurity:**
• K-means: Good baseline, assumes spherical attack patterns
• GMM: Better for overlapping/uncertain classifications
• DBSCAN: Ideal when attack patterns are irregular & you need anomaly detection
**Decision Framework for Cybersecurity Applications:**
**Choose K-means when:**
• You have a rough idea of number of attack types
• You need fast, interpretable results
• Attack patterns are roughly circular/spherical
**Choose GMM when:**
• You need uncertainty quantification
• Attack patterns have different shapes/orientations
• You want soft cluster assignments
**Choose DBSCAN when:**
• Unknown number of attack types
• Irregular attack patterns expected
• Automatic anomaly detection is priority
• Robust outlier handling needed
Check out the table that’s printed. You’ll see silhouette scores for each method. But don’t just look at the numbers - look at the actual clustering results. Sometimes a lower silhouette score is acceptable if the method is finding more meaningful clusters for your application. or in this case if your data is noisy.
Next Steps and Advanced Methods#

The Clustering Algorithm Landscape#
Today we covered three fundamental approaches but the clustering landscape is much larger:
Centroid-based: K-means, K-medoids, k-modes
Distribution-based: Gaussian Mixture Models (GMM)
Density-based: DBSCAN, OPTICS, HDBSCAN
Hierarchical: Agglomerative, Divisive
Graph-based: Spectral clustering
And many more…
Each has its place in the toolkit. Often times finding the right one is more art than science. EDA and exploration (i.e. trial and error) are your friend.
When Traditional Clustering Isn’t Enough#
The “Normal Behavior” Problem in Cybersecurity:
Network behavior changes constantly
Seasonal patterns (business hours, weekends)
Evolution of legitimate applications
New types of normal behavior emerge
Traditional clustering limitations:
Static models don’t adapt
High-dimensional feature spaces
Temporal dependencies ignored
Complex behavioral patterns
Look at this time-series visualization below. The color represents time. Notice how the “normal” behavior drifts over time? The static K-means model, trained on early data, becomes outdated. It may start flagging new normal behavior as anomalies because the model hasn’t adapted.
This is the motivation for next week’s topic: Deep Learning.
**The Challenge: Evolving Normal Behavior**
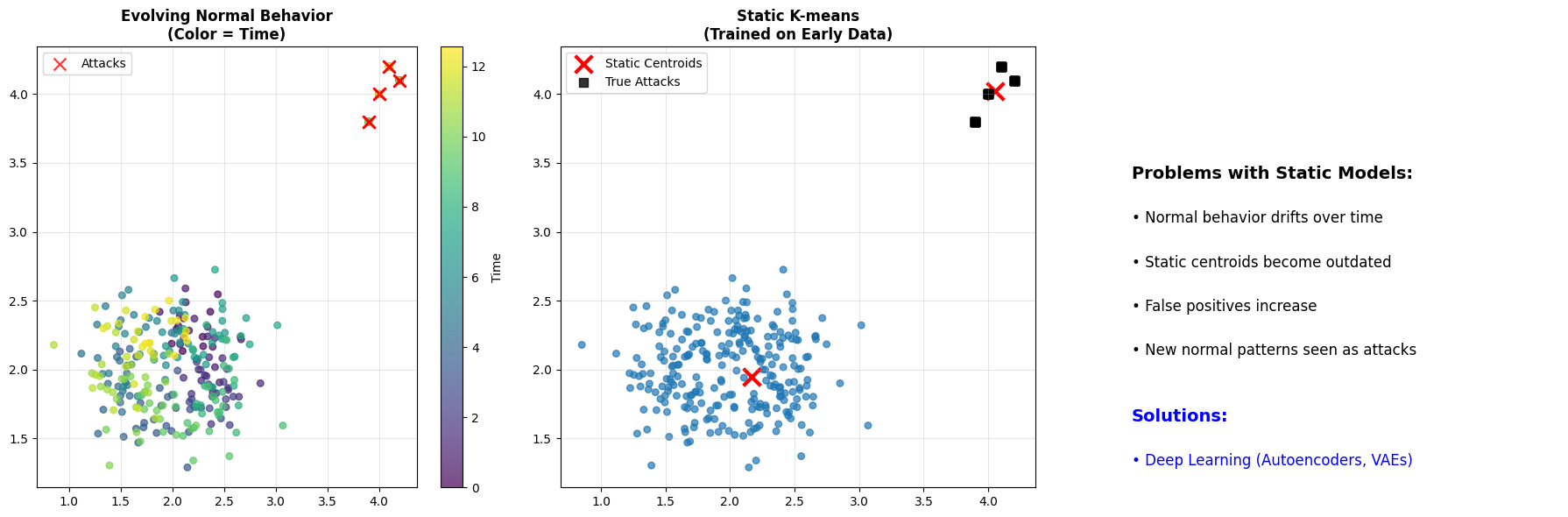
**The Evolution Challenge:**
• Normal behavior patterns change over time
• Static clustering models become outdated
• Need adaptive, continuous learning approaches
• Traditional methods struggle with high-dimensional, temporal data
============================================================
**PREVIEW: NEXT WEEK - DEEP LEARNING APPROACHES**
============================================================
**Why Deep Learning for Cybersecurity?**
• Handle high-dimensional feature spaces automatically
• Learn complex, non-linear patterns in data
• Adapt to evolving normal behavior
• Model temporal dependencies and sequences
**Methods we'll explore:**
• **Autoencoders**: Learn compressed representations of normal behavior
• **Variational Autoencoders (VAEs)**: Probabilistic generative models
• **Recurrent Neural Networks**: For temporal/sequential patterns
• **Graph Neural Networks**: For network topology analysis
**Real-world applications:**
• Advanced Persistent Threat (APT) detection
• Zero-day malware identification
• Insider threat detection
• Network intrusion detection systems
**Today's Foundation + Next Week's Power = Advanced Cybersecurity AI**
Summary: Key Takeaways#
Mathematical Progression#
K-means: \(\min \sum_{i=1}^{k} \sum_{x \in C_i} ||x - \mu_i||^2\) (Euclidean distance)
GMM: \(\max \sum_{i=1}^{n} \log \sum_{k=1}^{K} \pi_k \mathcal{N}(x_i | \mu_k, \sigma_k)\) (Probabilistic)
DBSCAN: Density-based, no global optimization function
Method Selection Framework#
Scenario |
Method |
Reason |
|---|---|---|
Known attack types, regular patterns |
K-means |
Fast, interpretable |
Uncertain classifications, overlapping |
GMM |
Probabilistic assignments |
Unknown threats, irregular patterns |
DBSCAN |
Auto-detects anomalies |
Evolving behavior, high-dimensional |
Deep Learning |
Adaptive, complex patterns |
Cybersecurity Insights#
No perfect clustering method - context and domain knowledge matter
Parameter selection is critical - elbow/silhouette methods provide guidance
Traditional clustering has limits - evolving threats need adaptive approaches
Next frontier: Deep learning for complex, temporal cybersecurity patterns
Next Session: Deep Learning approaches for advanced cybersecurity threat detection
Activity: Hands-on comparison of all three methods on real cybersecurity datasets (See Canvas)